Da bi skripte proradila potrebno je instalirati u terminalu sledeće zavisnosti:
pip install pdf2docx pip install mammoth
Potom formirajte Python3 skriptu za konverziju iz engleskog pdf-a u docx i nazovite je pdf2docx1.py
import argparse
from pdf2docx import Converter
# Parsiranje argumenata komandne linije
parser = argparse.ArgumentParser(description="Konvertovanje PDF u DOCX.")
parser.add_argument("input_file", help="Putanja do ulaznog PDF fajla.")
parser.add_argument("output_file", help="Putanja za izlazni DOCX fajl.")
args = parser.parse_args()
# Konverzija PDF u DOCX
try:
# Kreiranje konvertora i konvertovanje
converter = Converter(args.input_file)
converter.convert(args.output_file, start=0, end=None)
converter.close()
print(f"Konverzija završena! Dokument sačuvan kao {args.output_file}")
except FileNotFoundError:
print(f"Greška: Fajl '{args.input_file}' nije pronađen.")
except Exception as e:
print(f"Došlo je do greške: {e}")
Zatim formirajte skriptu docx2html.py koja docx prevodi u html jer iz docx može da pokupi sve tagove što direktno iz pdf-a veoma loše radi.
import mammoth
import argparse
# Parsiranje argumenata iz komandne linije
parser = argparse.ArgumentParser(description="Konvertovanje DOCX fajla u HTML.")
parser.add_argument("input_file", help="Putanja do ulaznog DOCX fajla.")
parser.add_argument("output_file", help="Putanja za izlazni HTML fajl.")
args = parser.parse_args()
# Konverzija DOCX u HTML
try:
with open(args.input_file, "rb") as docx_file:
result = mammoth.convert_to_html(docx_file)
html = result.value # HTML sadržaj
with open(args.output_file, "w", encoding="utf-8") as html_file:
html_file.write(html)
print("Konverzija završena!")
except FileNotFoundError:
print(f"Greška: Fajl '{args.input_file}' nije pronađen.")
except Exception as e:
print(f"Došlo je do greške: {e}")
Na kraju sve povežite sa Bash skriptom koju nazovite pdf2htm.sh
#!/bin/bash
# Proverava da li je argument prosleđen (ulazni PDF fajl)
if [ -z "$1" ]; then
echo "Morate uneti ulazni PDF fajl."
exit 1
fi
input_pdf="$1"
output_docx="${input_pdf%.pdf}.docx"
output_html="${input_pdf%.pdf}.html"
# Proverava da li postoji ulazni PDF fajl
if [ ! -f "$input_pdf" ]; then
echo "Ulazni PDF fajl nije pronađen: $input_pdf"
exit 1
fi
# Konvertuje PDF u DOCX koristeći pdf2docx1.py
echo "Konvertujem $input_pdf u $output_docx..."
python3 -m pdf2docx1 "$input_pdf" "$output_docx"
# Proverava da li je .docx fajl uspešno napravljen
if [ ! -f "$output_docx" ]; then
echo "Nije moguce konvertovati $input_pdf u $output_docx!"
exit 1
fi
# Konvertuje DOCX u HTML koristeći docx2html
echo "Konvertujem $output_docx u $output_html..."
python3 -m docx2html "$output_docx" "$output_html"
# Proverava da li je .html fajl uspešno napravljen
if [ ! -f "$output_html" ]; then
echo "Nije moguce konvertovati $output_docx u $output_html!"
exit 1
fi
echo "Proces zavrsen! Fajlovi su: $output_docx i $output_html"
Učinite izvršnom bash skriptu i pokušajte da je pokrenete sa nekim pdf fajlom na engleskom jeziku kao jedinim argumentom:
chmod +x pdf2htm.sh ./ pdf2htm.sh pdf_na_engleskom.pdf
Evo slikovnog primera pokretanja pdf2htm.sh sa_engleskim.pdf
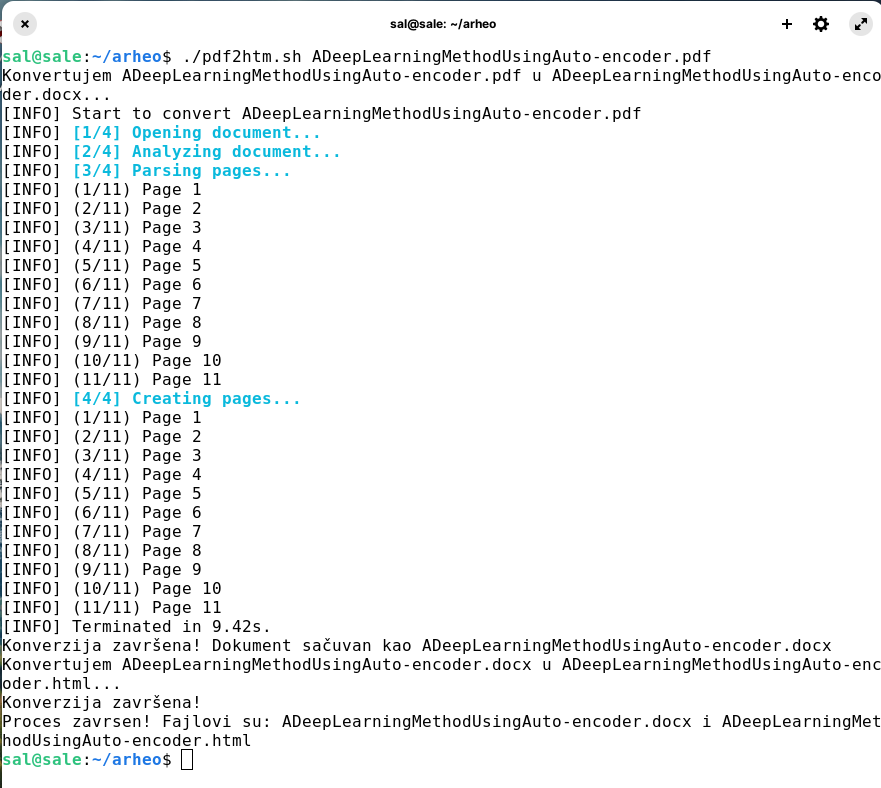
Dvoklikom na dobijeni html ADeepLearningMethodUsingAuto-encoder.html otvarate ga na Google Chrome i tamo ga opcijom Translate prevedete na koji želite jezik. Neophodno je potrebno da tekst skrolujete od početka do kraja u browseru da bi Google-ova veštačka inteligencija sve prevela, a onda prevedeni tekst opcijuom PRINT učitajte u PDF.
Dobijeni PDF otvorite i markirajte ceo tekst kombinacijom tastera Ctrl+A, zatim Ctrl+C i na kraju u otvoreni (u mom slučaju) WPS Word u novootvoreni dokument kopirajte sa Ctrl+V. Dobijeni dokument možete doradite kako bi bio vizuelno što verniji originalnom engleskom tekstu. I tako dobijete prevedeni dokument u Docx formatu koji možete dalje da koristite.