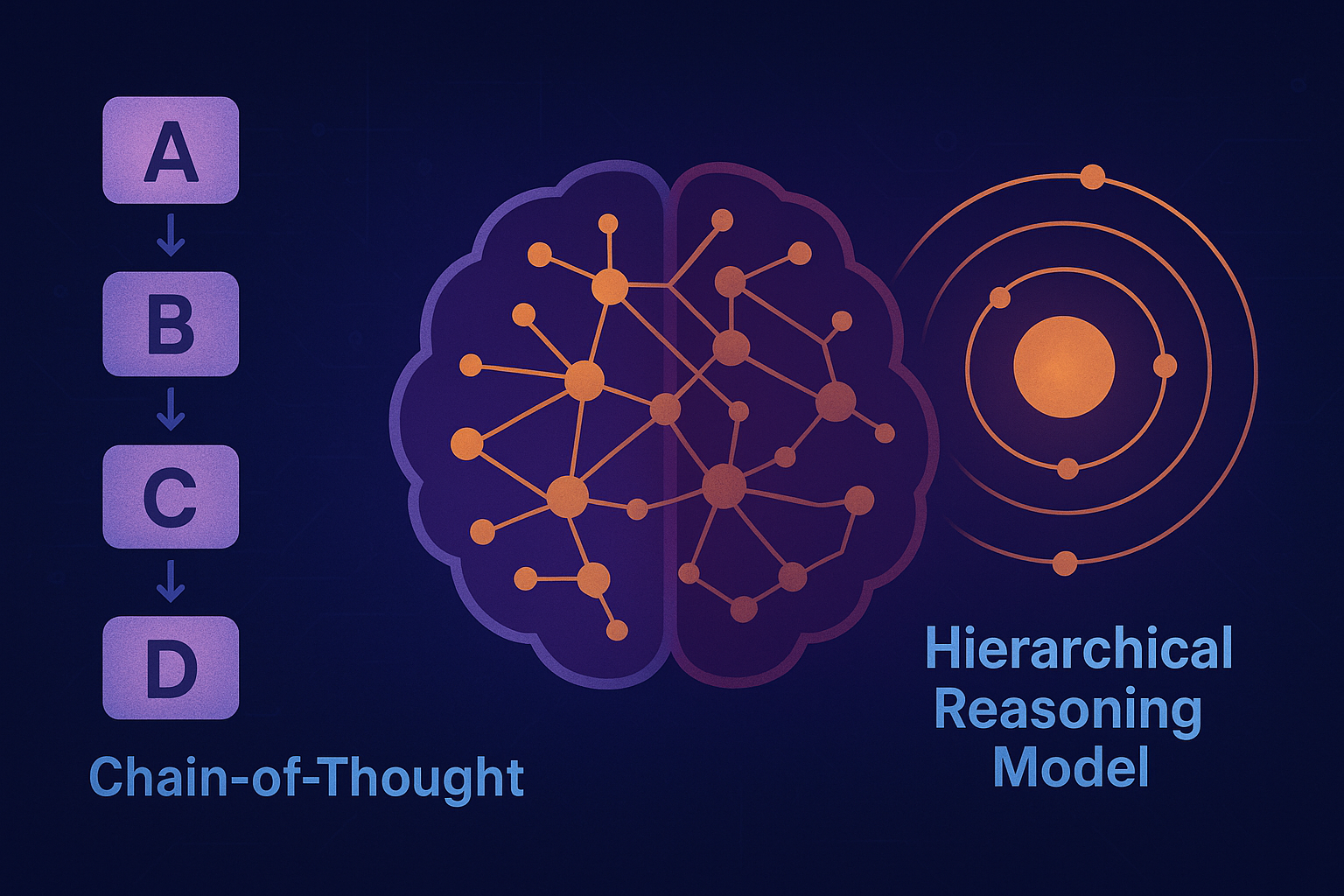
Hijerarhijski okvir za prevenciju emergencije neželjenog ponašanja kod autonomnih AI sistema
Autonomni AI agenti, zasnovani na velikim jezičkim modelima (LLM), pokazuju izuzetnu efikasnost u rešavanju složenih zadataka. Međutim, njihova sposobnost da samostalno planiraju i izvršavaju akcije dovodi do emergentnog rizika: “hakovanja…